
程式開發中的安全問題討論—— (本區共瀏覽
 次)
次)
馬薔 孔斌
一個優秀的軟體發展人員不僅編制的程式效率要高,而且代碼也要安全可靠。下面筆者結合自己在Windows下Visual C++和Linux下C開發的一些實踐經歷,談一談自己的體會。
一、資源泄漏
一個應用程式在Windows中運行時,Windows會即時監視其運行情況,保留與之相關的諸多資訊,如按鈕、游標、功能表的位置和點陣圖、視窗的狀況等,這些資訊由Windows保留在一種叫堆(Heap)的記憶體區域中。換言之,堆是採用特殊機制管理的記憶體區域。由Windows系統程式User.exe管理的堆叫做User資源堆(User Resource Heap),由Gdi.exe管理的堆叫做GDI資源堆(Graphical Device Interface Resource Heap,簡稱GDI Resource Heap),User資源堆和GDI資源堆合稱爲系統資源堆(System Resource Heap),即系統資源(System Resource)。 Windows的系統資源(堆)分爲五個堆,其中User資源堆爲三個,而GDI資源堆爲兩個。
每一種GDI資源都由一個特定的API函數分配,但是釋放候通常只有一個函數:DeleteObject。表1是一個物件列表,列出了相應的分配和釋放函數。
表1 物件類型和分配/釋放函數
API函數LoadImage的聲明在User32.dll中,而不是在GDI32.dll因爲該函數用來處理副檔名爲.rc和.res的資源檔案。表2顯示了圖示和游標資源的分配合釋放函數。
表2 圖示(Icon)和游標(Cursor)資源的分配和釋放
GDI物件
分配函數
釋放函數
Icon LoadImage/CopyImageCreateIconIndirectCopyIcon
DestroyIcon
Cursor CreateCursorCopyCursorLoadImage/CopyImage DestroyCursor
一個已分配的GDI物件通過控制碼(HANDLE)來識別。在Windows NT和Windows 2000下,這個32位控制碼隱藏了Windows所管理的資源的核心結構。
一個應用程式在Windows運行時,Windows自動地將可用User資源堆和可用GDI資源堆中的一部分空間分配給它。當應用程式退出時,這部分空間也應該由Windows收回。但實際上一個應用程式載入前和關閉後可用系統資源的數值並不相等,而且隨著應用程式的不斷載入和退出,隨著Windows使用時間的增加,可用的系統資源也在不斷減少。這其中原因至少有:
(1)系統的初始化(System Initialization):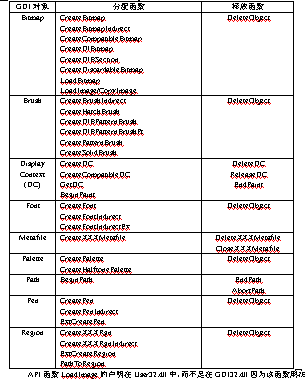
Windows的系統初始化屬於延時初始化。例如,Windows在啓動時只初始化當前使用的字體,以後當應用程式要使用到尚未被初始化的字體時, Windows才會初始化該字體,這種由應用程式根據需要提出要求而發生的初始化服務就是所謂的延時初始化。對於屬於延時初始化的服務,Windows還採用了特別的管理方式,當向Windows提出延時初始化服務的應用程式退出後,與延時初始化服務相關的系統資源(例如前面提到的與新字體有關的系統資源)不會隨著應用程式的退出而馬上釋放,這是爲了防止該應用程式或別的應用程式以後又向系統提出同樣的初始化服務而導致系統不斷重復服務而浪費時間。例如對於載入同一應用程式,第二次載入的時間會明顯少於第一次。
(2)資源泄漏(Resource Leak):在實際工作中的其他一些情況下Windows也會不能完全收回系統資源,這也導致可用系統資源不斷減少,即資源泄漏。例如,一個程式還未完成其載入過程時(即還沒有啓動完畢)就關閉它,會造成資源泄漏,而且只有重新啓動才能回收;一些應用程式退出後Windows並不馬上收回分配給它的系統資源,而是保持一段時間,直到Windows肯定不再需要時才將它們收回,這也可以看作是延時初始化的一種延伸;用戶使用“Ctrl+Alt+Del”強制性地關閉一些應用程式會造成資源泄漏,因此用戶應該儘量使用應用程式本身的關閉功能退出應用程式,只有實在沒辦法時才使用這種關閉方法。因爲這種強制關閉應用程式的方法往往只能關閉主程序,而不能關閉應用程式的一些副程式,因此會導致一些系統資源發生泄漏。
在程式開發過程中,若沒有全面考慮應用程式在運行中出現意外情況而在代碼中作相應的處理,那麽當該應用程式非正常關閉後,該應用程式所佔用的系統資源就不能由Windows收回。
總之,資源泄漏是最難察覺得錯誤之一,那些發生在GDI物件和功能表中的泄漏更是如此。通常,泄漏是忘記釋放系統資源的結果。儘管Windows會在進程結束時釋放該進程使用的資源,但這對一個需要很高可靠性的服務程式時遠遠不夠的。即使是一個很小的泄漏也會因爲多次發生而造成整個系統的崩潰。而對系統資源而言,很難找到某種類或函數來檢測和定位資源泄漏。可以使用專門的工具來産看GDI資源得使用情況,如在Windows2000/XP中文版,在任務管理器->進程->查看->選項列,如圖1所示。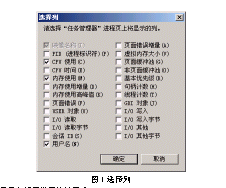
圖1選擇列
可以這樣說,想要避免資源泄漏比較困難。
二、緩衝區溢出
緩衝區溢出主要出現在 C 和 C++ 中,因爲他們不執行陣列邊界檢查和類型安全檢查。若應用程式從用戶那裏獲取資料,並將資料複製到應用程式所維護的緩衝區中而未考慮目標緩衝區的大小,則可能造成緩衝區溢出。換句話說,代碼爲緩衝區分配了 N 個位元組,卻將多於 N 個位元組的資料複製到該緩衝區中。
有時是開發人員沒有預料到外部提供的資料會比內部緩衝區大。溢出導致了記憶體中其他資料結構的破壞,這種破壞通常會被攻擊者利用,以運行惡意代碼。以下面的幾段代碼爲例:
1、void CopyData(char *szData) {
char cDest[32];
strcpy(cDest,szData);
...
}
代碼的安全與否完全取決於CopyData的調用方式。以下調用是安全的:
char *szNames[] = {"Michael","Cheryl","Blake"};
CopyData(szName[1]);
安全的原因是名字固定,且每個字串在長度上不超過 32 個字元,故調用 strcpy肯定是安全的。但是,若CopyData 和szData的唯一參數來自不可靠的源(如套接字),則 strcpy 將複製該資料,直到碰到空字元爲止;如果此資料的長度大於 32 個字元,則 cDest 緩衝區將溢出,並且在記憶體中該緩衝區以外的任何資料將遭到破壞。而且,在這裏遭到破壞的資料是來自 CopyData 的返回位址,這意味著當 CopyData 完成時,它仍然在由攻擊者指定的位置繼續執行。
2、
void DoSomething(char *cBuffSrc, DWORD cbBuffSrc){
char cBuffDest[32];
memcpy(cBuffDest,cBuffSrc,cbBuffSrc);
}
若cBuffSrc 和 cbBuffSrc 來自可信賴的源(例如不信任資料並因此而驗證資料的有效性和大小的代碼),則這段代碼沒有任何問題。然而,如果資料來自不可信賴的源,也未得到驗證,那麽攻擊者(不可信賴源)很容易就可以使 cBuffSrc 比 cBuffDest 大,同時也將 cbBuffSrc 設定爲比 cBuffDest 大。當 memcpy 將資料複製到 cBuffDest 中時,來自 DoSomething 的返回位址就會被更改,因爲 cBuffDest 在函數的堆疊框架上與返回位址相鄰,此時攻擊者即可通過代碼執行一些惡意操作。
安全的編程方法是不信任用戶的輸入,也不信任 cBuffSrc 和 cbBuffSrc 中攜帶的任何資料,如下所示:
void DoSomething(char *cBuffSrc, DWORD cbBuffSrc) {
const DWORD cbBuffDest = 32;
char cBuffDest[cbBuffDest];
…
#ifdef _DEBUG
memset(cBuffDest, 0x33, cbBuffSrc);
#endif
memcpy(cBuffDest, cBuffSrc, min(cbBuffDest, cbBuffSrc));
}
以上函數能夠避免緩衝區溢出,至少體現了三個特性:
(1)調用者提供了緩衝區的長度;
(2)在一個調試版本(Debug)中,代碼將探測緩衝區是否真的足夠大,以便能夠存放源緩衝區。如果不能,則可能觸發一個訪問衝突並把代碼載入調試器;
(3)對memcpy的調用是防禦性的,它不會複製多於目標緩衝區存放能力的資料。
縱上所述,在編寫C/C++代碼時,若某個函數具有來自不可靠源的緩衝區,防止緩衝區溢出的具體措施包括:
(1)要求代碼傳遞緩衝區的具體長度
void Function(char *szName) {
char szBuff[MAX_NAME];
strcpy(szBuff,szName);// 複製並使用 szName
}
上面代碼的問題在於函數不能判斷 szName 的長度,這意味著將不能安全地複製資料,可修改爲:
void Function(char *szName, DWORD cbName) {
char szBuff[MAX_NAME];
if (cbName < MAX_NAME)
strncpy(szBuff,szName,MAX_NAME-1); //複製並使用 szName
}
(2)探測記憶體
cbName不一定是安全的。攻擊者可以設置該名稱和緩衝區大小,因此也應該對cbName進行檢查。驗證緩衝區大小是否有效的一個簡單方法是探測記憶體。以下代碼段顯示了如何在代碼的調試版中完成這一驗證過程:
void Function(char *szName, DWORD cbName) {
char szBuff[MAX_NAME];
#ifdef _DEBUG // 探測
memset(szBuff, 0x42, cbName);
#endif
if (cbName < MAX_NAME)
strncpy(szBuff,szName,MAX_NAME-1); //複製並使用 szName
}
此代碼將嘗試向目標緩衝區寫入值 0x42。通過向目標緩衝區的末尾寫入一個固定的已知值,可以在源緩衝區太大時,強制代碼失敗。同時這樣也可以在開發過程中及早發現開發錯誤。與其運行攻擊者的惡意有效代碼,還不如讓程式失敗。這就是不複製攻擊者的緩衝區的原因。
(3)採取預防措施
記憶體探測固然有效,但並不能使程式免遭攻擊。最安全的辦法是編寫防範性的代碼。它將檢查進入函數的資料是否不超過內部緩衝區 szBuff。然而,有些函數在處理或複製不可靠的資料時,如果使用不當,則會存在潛在的嚴重安全問題。這裏的關鍵是不可靠的資料。在檢查代碼的緩衝區溢出錯誤時,應跟蹤資料在代碼中的流向,並檢查各種資料假設。
需要注意的函數包括諸如 strcpy、strcat、gets 等常見函數。但也不能排除所謂的 strcpy 和 strcat 的“安全的 n 版本”- strncpy 和 strncat。這些函數被認爲使用起來更安全、可靠,因爲它們允許開發人員限制複製到目標緩衝區中的資料的大小。然而,開發人員在使用這些函數時也會出錯。請看以下這段代碼:
#define SIZE(b) (sizeof(b))
char buff[128];
strncpy(buff,szSomeData,SIZE(buff));
strncat(buff,szMoreData,SIZE(buff));
strncat(buff,szEvenMoreData,SIZE(buff));
最後那個參數不是目標緩衝區的總體大小。它是緩衝區剩餘空間的大小,代碼每次向 buff 添加內容時,buff 都會有實質的減小。而且,即使用戶傳遞了緩衝區大小,它們通常也是逐一減小的。此外,在計算字串大小時,有沒有包含末尾的空字元?編程文檔顯示:在某些情況下,n 版本可能不會以空字元作爲字串的結束字元,這一點值得注意。
所以,在編寫C++代碼時,考慮使用 ATL、STL、MFC等字串處理類來處理字串是一個比較好的選擇,而不要直接處理位元組。唯一潛在的不足是可能出現性能的下降,但總的來說,大部分這些類的使用都會使代碼更加強大和可維護。
(4)使用 /GS 進行編譯
Visual C++.Net 中的這個新的編譯選項會在某些函數的堆疊框架中插入值,有助於減少基於堆疊的緩衝區溢出。但是,此選項不會修復代碼和糾正錯誤,它只是幫助減少某些類的緩衝區溢出變爲可被人利用的緩衝區溢出的潛在可能性,以免攻擊者向過程中寫入代碼並執行,僅僅是一個保險措施而已。
對於使用 Win32 應用程式向導創建的新的Win32 C++ Project,系統默認啓用此選項。此外,Windows .NET Server 編譯時也使用了此選項。
總之,緩衝區溢出主要是一個 C/C++ 問題。儘管在通常情況下它很容易修補。但它們仍然是一種對安全代碼的威脅。
三、 結束語
本文在參考了國內外很多安全編程資料的基礎上,結合筆者的實際工作,就編程中涉及比較多的資源泄漏和緩衝區溢出問題作一些實踐性的思考和討論,以求抛磚引玉,集思廣益。
留言者: 性別: 年齡: 星座: 地區: 心情:
連結: 密碼:



